提高匹配度之短语匹配
DisMax/eDisMax 有个 pf 参数,如下
pf
pf 设定了多个短语匹配加权的字段:把 q 参数的值视为一个短语,pf 参数所指定的字段如果能匹配到该短语,会增加其匹配度权重。
什么是短语
hello world分词以后得到 2 个词条:hello和world,但是如果我想要查询的是整个hello world呢?可以用引号"hello world"来表示这是个短语,就不会被分词了
注意:
- pf 参数会把整个
q参数的值视同一个短语来做加权匹配,不论参数前后木有引号,你没有必要自己再加上引号 - 但这不是说只有短语匹配的文档才是搜索结果,根据搜索引擎的算法,默认情况下任意一个词条被匹配都是可以滴(除非你设置了 mm 值或其他的参数)
- 也不是说只在
pf指定的字段里搜索,如果没有在q参数里指定字段,那么搜索是在默认的字段里做匹配
pf 参数格式如下
字段1^加权因子1 字段2^加权因子2 ...
示例
pf=name^2 desc^0.8 actor
如果不指定加权因子,默认为 1
什么叫匹配到短语呢?例如,有如下几个文档
1. hello world solr
2. hello solr world
3. solr world hello
4. world solr hello
查询条件为 q=hello world
- 如果短语匹配加权,文档 1 的匹配度会大于其他文档,因为文档 1 做到了短语匹配;
- 如果短语匹配不加权,那么所有文档的匹配度是一样滴,因为大家都做到了词条全匹配
例子
我们来看个例子,将如下 2 个文档添加到 tv 里
albums = (
Album('钢铁托尼侠', '短语匹配加权1', ),
Album('钢铁侠托尼', '短语匹配加权2', )
)
然后查一下

可以看到在标准查询模式下 2 个文档的分数是一样一样滴,但以人类的逻辑来说,钢铁侠托尼应该比钢铁托尼侠更要匹配才对,怎么让 solr 做到呢?
用 eDisMax 的短语匹配加权来试一下吧

注意图上荧光笔涂抹的部分,搜索关键字不变,使用 eDisMax 并设定 name 字段为短语匹配加权字段后,可以看到 2 个文档的得分明显拉开了差距
pf 字段必须索引
那么,如果该字段没有建索引能生效吗?我们来试一下,将文档的 name 和 desc 字段值交换一下
albums = (
Album('短语匹配加权1', '钢铁托尼侠', ),
Album('短语匹配加权2', '钢铁侠托尼', )
)
我们先确认一下,desc 字段是没有索引滴
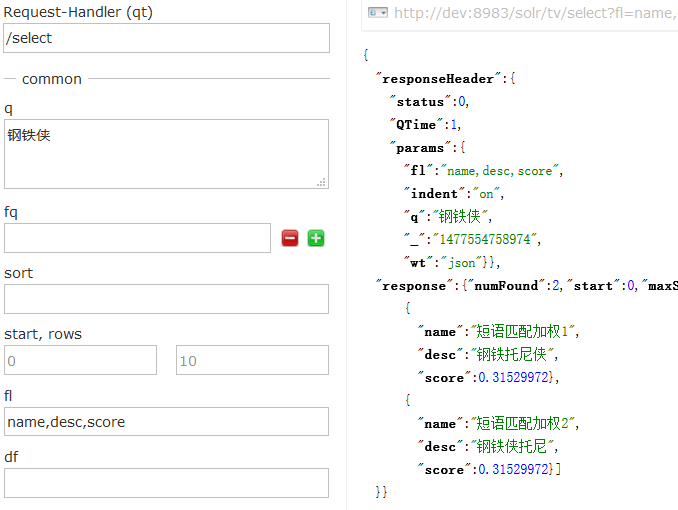
先用标准查询解析器搜索,结果如下图,2 个文档的分数还是一样滴
然后,在用短语匹配字段 pf=desc 的试下,结果如下
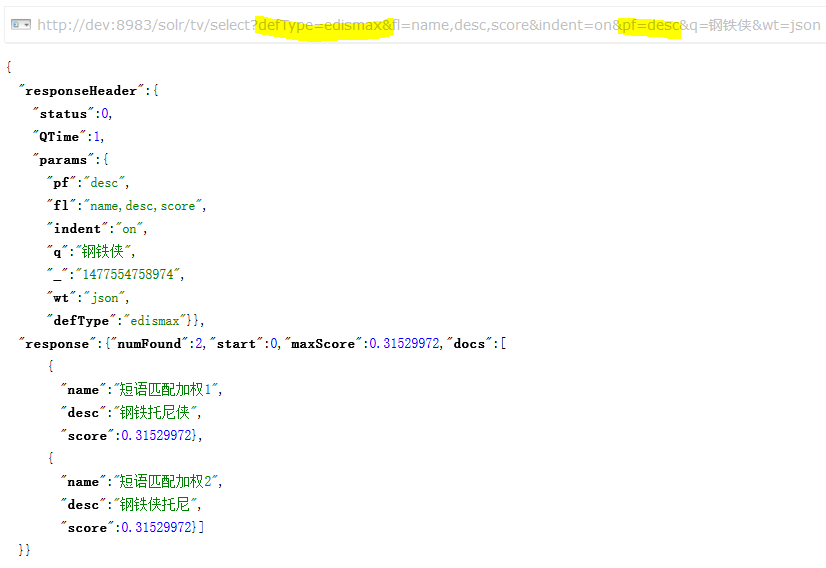
可以看到该参数对于非索引字段是无效滴
结论
pf指定的字段必须建索引,否则被忽略q参数的值作为短语,在pf指定的字段里去做匹配,如果有匹配就会提升文档的匹配度- 不论
pf参数是啥,搜索本身不受影响,即原来搜不到的还是搜不到,原来能搜到的照旧能搜到;pf影响的是结果的排序